Tuesday Feb 17, 2026
Tuesday Feb 17, 2026
Friday, 17 January 2020 00:10 - - {{hitsCtrl.values.hits}}
Sinhala and Tamil are categorised under complex scripts at the time Unicode technology was created to render them on computers. Sinhala had taken a long and arduous computerisation journey, in the 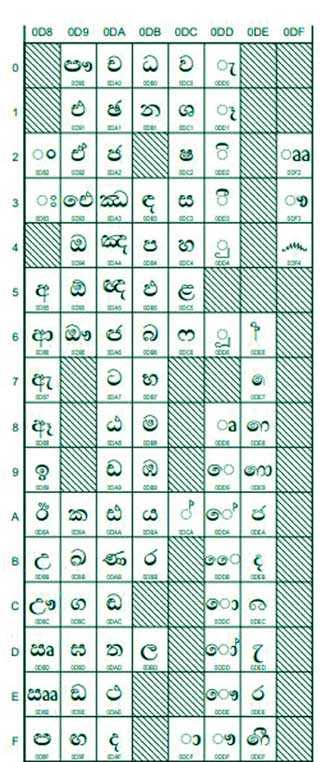 outcome of which it stands on its own shoulder to shoulder with English in the operations of Sinhala Script on computers. Sinhala can be stored with any other script in parallel in a document and a list of Sinhala words can be sorted and arranged according Sinhala collation sequence like any other Latin Script, and it has become an ordinary day to day occurrence that data in Sinhala is stored in a Database Management Systems (DBMS) like data in English. Spell checkers are already developed, and grammar checkers are also on the way for Sinhala.
outcome of which it stands on its own shoulder to shoulder with English in the operations of Sinhala Script on computers. Sinhala can be stored with any other script in parallel in a document and a list of Sinhala words can be sorted and arranged according Sinhala collation sequence like any other Latin Script, and it has become an ordinary day to day occurrence that data in Sinhala is stored in a Database Management Systems (DBMS) like data in English. Spell checkers are already developed, and grammar checkers are also on the way for Sinhala.
Theekshana R&D and the Language Technology Research Laboratory (LTRL) of University of Colombo School of Computing (UCSC) have been working on Optical Character Recognition (OCR) and Text to Speech for more than 10 years and this research output is about to be released as commercial products.
Sri Lanka created history in 2011 by releasing Non-Latin Country Code Top Level Domain Names (ccTLDs) “ලංකා” and “.இலங்கை” and they are now active ccTLDs for the last eight years managed by the LK Domain Registry. It was last year that I co-chaired ICANN Sinhala Generation Panel of ICANN to release rules for top level domains in Sinhala. All these are great achievements not known by the ordinary public using Sinhala on their computers, which would not have been possible without Unicode. The objective of this article is to present an introduction to Unicode while paying attention to SLS 1134 Third Revision which provides the standard for input of Sinhala using the Wijesekera Keyboard.
Unicode Standard or Universal Encoding Standard
Before the introduction of the Unicode Standard, numerous encoding standards which were unique to each language or group of languages had been introduced worldwide. American Standard Code for Information Interchange (ASCII), also known as ISO 646 group of standards, was a seven-bit character  encoding which was developed in 1964 and released its first version in 1967 to store a Latin Character set.
encoding which was developed in 1964 and released its first version in 1967 to store a Latin Character set.
Based on ASCII, several other countries also released similar standards for their countries. India released the Indian Standard Code for Information Interchange (ISCII), an eight-bit code supporting several Indian character sets such as Assamease, Bengali, Devanagri, Gujarati, Marati, Malayalam, Tamil, Telagu etc. Following in the footsteps of India, Sri Lanka had also released the Sri Lankan Standard Code for Information Interchange (SLASCII) in 1990. In SLASCII, lower 128 code points had the Latin character set encoded and the upper code points had the supporting of the Sinhala character set.
The world has more than 50 written scripts with different characteristics. Most European languages are written in Latin script. Russian, which belongs to Slavic family of languages, is written in a script known as Cyrillic, and both of these scripts belong to family of scripts called the Alphabetic Group of scripts. Hebrew and Arabic, which belong to a family of Sematic Languages, are written from right to left and are written from right to left and are bidirectional scripts known as Abjad scripts. Arabic had been a challenge to computerise, unlike Alphabetic scripts.
Sinhala, Tamil and Hindi are written with scripts that had originated from Brahmin script and are phonetic in nature. These scripts are also known as complex scripts, or Abiguda Scripts, which have vowel modifiers modifying consonants. Some scripts in this family are very complex, like Dzongkha which is the official script of Bhutan. Dzongkha is one of the most complex scripts in the world and can stack up to six levels, whereas Sinhala has only single level stacking with vowel modifiers occurring together or alone either side of a consonant and/or top and below it.
To have texts in different languages like Sinhala and Tamil in a single page had been challenge before the introduction of Unicode or Universal Character Encoding standard. Before the advent of Unicode, texts were stored using fonts which had numerous encoding standards as mentioned in the beginning of this article.
When written using a particular font in the early days of text rendering, the font has to be shipped with the text or URL has to be given to download the font. Without the specific font with which the texts were created, all that would be shown was gibberish.
This problem of having all scripts encoded was solved in 1990 after a long deliberation of the initial Unicode group which consisted of Joe Decker from Xerox, Mark Davis from Apple and Ken Whistler etc. The solution initially had been a simple 16-bit character model. In this model, the first byte identifies the language and the second byte stores the character. For instance, “0D” gives Sinhala as the Language and 85 indicates “අ” as the character. In this solution, Unicode is not only a font-based solution but it was designed as a technology where Unicode supporting fonts both True Type Fonts (TTF) and Open Type Fonts (OTF) requires a rendering engine. Several rendering engines have been released by different operating systems at present, such as Microsoft Windows’s Uniscribe and Linux’s Pango and QT among others.
Today, Unicode has become more versatile, and the standard has been expanded to include character sets of dead languages as well. Chinese, Japanese and Korean (CJK) have been encoded with more than 50,000 characters for each language, since these are pictorial scripts. Basic Multilingual Plane (BMP) or plane 0 which has all the living characters – Sinhala is in the OD segments of BMP – and supplementary levels consist of many characters that are at present not in use. For instance, the Supplementary plane has Sinhala ‘Illakkam’ which is a set of numerals that is not in use in modern Sinhala.
Presently, UTF 8, UTF 16 and UTF 32 dominate the web and languages are added to the Unicode on a daily basis. Sinhala was slow to be encoded initially and the Unicode Consortium had to be convinced at several ISO/IEC Working Group 2 (WG2) meetings to incorporate a proper alphabetical sequence for Sinhala encoded in the Unicode.
Originally removing two vowels which are not found in the other languages of the Indic family was proposed, to remove breaking the Alphabetic sequence and move to the bottom of the Sinhala code chart. To this, the Government intervened and proposed that the sequence be maintained, and Sinhala was finally encoded in 1999. The Government of Sri Lanka intervened again to have hitherto forgotten numeral sets encoded in Unicode by 2013. The Information and Communication Technology Agency of Sri Lanka (ICTA) became the pivotal Government agency in this encoding as well as the release of the second and third revisions of SLS 1134.
It must be emphasised that, contrary to popular belief, Sinhala Unicode is not only an encoding for Sinhala characters; it is also a digital alphabet for Sinhala.
(By R&D COO Theekshana and CTO Harsha Wijayawardhana B.Sc., FBCS, in collaboration with LK Domain Registry.)


