Tuesday Feb 17, 2026
Tuesday Feb 17, 2026
Thursday, 11 July 2019 00:00 - - {{hitsCtrl.values.hits}}

A famous quote by Charles Darwin states: “It is not the strongest or the most intelligent who will survive, but those who can best manage change.” Darwin, back in the 19th century, has pretty much summed up the present-day reality of the global financial ecosystem in one sentence.
Technological disruptions have made a profound impact on the global financial landscape, changing the way people and businesses as well as governments work. It has forever changed the way we live and how we experience the world. 
Big data and Artificial Intelligence (AI) have become buzzwords in modern-day conversations. No sector is immune to the rapidly-changing digital technology and disruptions caused to the traditional way of life. Technology has brought the human effort of months and years into a matter of hours in generating viable information.
Human creativity and analytical capability is being replaced by software. Process automation software are rapidly enhancing capabilities, creating a digital employee with seamless interaction with human employees. The World Economic Forum in its report on ‘Future of Jobs and Skills’ says that 65% of children entering primary school today will end up in completely new job types that do not exist at present. It’s not the elimination of jobs, it is about elimination of tasks.
The secret of the roots of this disruptive force rests in four letters – data. The volume of data created daily in the globe is estimated to be 2.5 exabytes, i.e. is 2.5 billion gigabytes. Organisations which are capable of interpreting the secrets hidden with these massive datasets hold the key to the lead role of any industry. Light bulb moments and innovation through data interpretation can redefine an industry in a matter of seconds. In time to come, data will redefine the shape of the present-day balance sheet of business, as the most valuable asset.
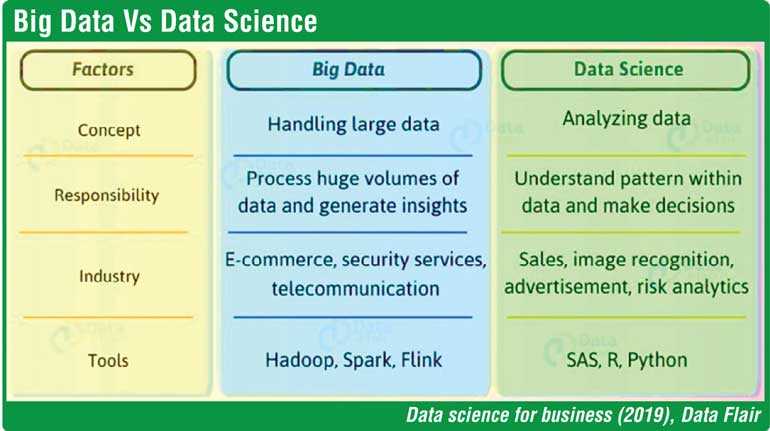
Data vs. data science
The rise of the online era of doing things, the interactive platforms we use in day-to-day life, be it Facebook, YouTube or Amazon, are left with our digital footprints. These records, transaction logs and social media unleash an unimaginable amount of data to the world.
As per the famous quote of IBM, 90% of world data was created during the previous two years. It was an eye-opener for the level of dramatic growth of data. The data can be identified as structured data, generated through websites and mobile devices, and unstructured data, generated from users, such as online reviews, chats and emails.
The volume of data is big. So what is big data? It is all about handling and managing this massive volume of structured as well as unstructured data. Prior to the concept of big data, even when the data was there, there weren’t adequate resources and tools for their effective management.
The publication of the technical paper by Jeffery Dean and Sanjay Ghemawat of Google, titled ‘Mapreduce: Simplified Data Processing on Large Clusters,’ marks the emergence of contemporary big data. The paper was on Google’s approach in web data collection and analysing. The programming model introduced in this paper, Mapreduce, was later developed into an open source big data tool, Hadoop. Data mining is the most common word goes hand in hand with big data.
Data mining refers to extracting data from a large database using statistical models to generate specific business information. Usama M. Fayyad, a prominent US data scientist, in his 1996 publication, ‘Data Mining to Knowledge Discovery in Databases,’ talked about the overall process of discovering useful information from data. It mentioned data mining is a part in the larger process.
In basic terms, big data deals with storing and management of large volume of data and data mining provides limited business information. However, the need for scientific analysis of these data and drawing insights for business decision making became the top priority in the competitive global environment. Everyone needs a breakthrough, an edge over others, to fast track their success story.
In 2001, William Swain Cleveland, an American computer scientist, first introduced this ground-breaking concept to the world. He went a step further from Fayyad, combining data mining with computer science. He named this new collaboration as data science. So what is data science actually?
The Journal of Data Science defines data science as: “Almost everything that has something to do with data, collecting, analysing, modelling. Yet the most important part is its application – all sorts of applications.”
Data science is a multidisciplinary subject area combining mathematics, statistics as well as computer science. The data scientist is the person who use variety of tools such a SAS and Python to derive information, hidden patterns from a data set. They will interpret, visualise and develop hypothesis on different scenarios on business decision making. Data science has become a viable and practical solution for business development with the development of open source software at minimum cost, development of algorithms and no limitations of data storage volumes.
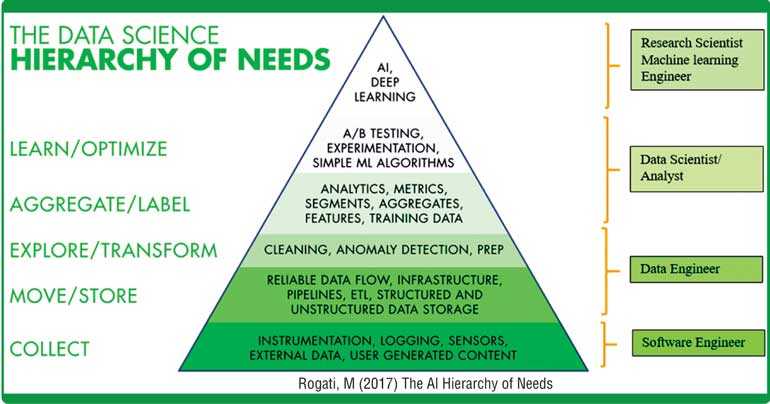
The examination of the data science hierarchy of needs we can observe that the most popular buzzwords in the present-day context, Artificial Intelligence (AI), deep learning and machine learning, are only a part of data science. The data-driven decision-making applies to a variety of sectors. Some of them are healthcare, ecommerce, manufacturing, transportation and banking and finance.
Data science in banking
The professional services network Deloitte’s report on ‘Banking Industry Outlook – 2019’ mentioned that the total asset base of the banking industry alone is $ 123.7 trillion. It shows the domination of the banking sector over the global economy. The application of data science into banking can revolutionise the industry and change the present shape forever.
Data science enables the industry to make fast and accurate business decisions which are specifically data-driven. The success probability of corporate strategies forecasted backed by data analytics will be high with dynamic and responsive business intelligence systems.
The performance measures of the banking institutions will enter a novel era as the evaluation and quantification of performance will be determined based on selected high responsive metrics. The leadership development will come into the spotlight as performance tracking and success rate of decisions are under the purview of analysis based on data science.
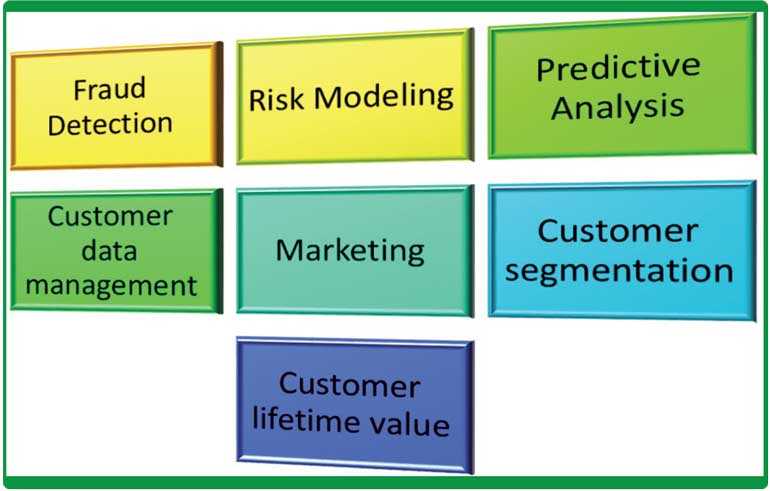
The application of data science into banking can be segmented into seven key areas. They are the use of data science for detection of fraud, risk management, predictive analysis, customer data management, marketing, customer segmentation and new customer acquisition and customer life time value assessment.
Application of data science in banking – New frontiers
Fraud detection
The Global Banking Fraud Survey Report, May 2019, by KPMG revealed that bank fraud value as well as volume has increased over the past years. These frauds include credit card fraud, identity theft, and push payment scams. As per the report more than 50% of the respondents recovered less than 25% of the losses from fraud. It highlights the importance of taking proactive measures to prevent bank fraud rather than reactive to the fraud event. KPMG says that the global banking industry is moving towards new technologies such as machine learning and real-time fraud alert as a defence.
Financial institutions in general lose 5% of their annual income to fraud in approximate terms. In terms of banks, this cost spread in a wider angle customer confidence and regulatory actions. Data science, inter alia use for monitoring and prevention of credit card fraud, insurance-related fraud and accounting fraud.
Banks possess a massive amount of transaction data of their customers. Banks can apply machine learning to fraud detection and prevention. That is banks can use their historical data to train a statistical algorithm to identify patterns and generalise knowledge. The trained model will evolve itself with the infusion of new real time data, which is the machine learning process. Global banks tend to use algorithms such as K-Means for clustering and SVM for building a model to identify patterns.
For instance, machine learning algorithm can create alerts on suspicious account activity leading to money laundering based on deposits, withdrawals and fund transfer patterns. In another instance, if a credit card is generating online transactions in quick succession, there is a risk that the card may have been hacked. Machine learning can be used to block such transactions.
Data analysis is vital not only because it detects frauds, but also it enables auditors and regulators to gain insight on the effectiveness of the internal control systems of the bank.
Risk modelling
Banking industry and risk are two sides of the same coin. More the financial innovation, more the risk. Risk modelling has the potential to touch areas such as treasury activities and wealth management as well as investment arms of a bank.
However, in the present context, risk modelling is more focused on credit risk of a bank. Under this, banks are empowered for an in-depth analysis of their credit portfolios, allowing them to identify growth patterns and repayment patterns as well as risk of non-performing loans. Banks can develop various pre-emptive strategies to mitigate non-performing risk of their credit portfolio. Banks can classify customers based on the result of the credit risk model when considering further facilities. Provided the general economic conditions are improved, this kind of solution can be effectively executed in the Sri Lankan banking industry to manage high levels of bank NPA.
Predictive analysis
Machine learning can be used to forecast a given future event with a high success probability. This enables a bank to manage the given future event profitably or avoid any losses to the bank. One area of focus is cash flow management. Machine learning can be used to predict the future cash flow requirements, enabling the bank to optimise the balance between liquidity and profitability.
Customer centric approaches
Data science is increasingly used in the banking industry for customer data management, customer segmentation and evaluating customer lifetime value (CLV).
Banks use the help of data science to generate business intelligence out of the customer databases they possess. Machine learning can be used to transform data and extract vital information, which provides insights into a variety of aspects of customer behaviour. Customer segmentation also goes hand in hand with this.
Data science can be used to track the common characteristics of customers. For example, which customers use online banking, which customers use cards for online purchases, Deposit volume of customers and their loan and credit card liabilities, etc. Based on these, banks can categorise customers into a high to low value scale. Based on that banks can customise their product offering, modify and improve banking services to appeal specific segment, etc.
CLV is the entire value a bank gets during the period where the banker customer relationship exists. Classification algorithms give an insight in to the cost of customer retention as well as the suitability of resource allocation for customer retention as well as new customer acquisition. Predictive analysis also plays a role in this aspect, forecasting the future value of a potential customer.
Marketing
The online behaviour of customers is a vital input for banks to design their marketing activities. Customer activities in internet purchases, bank’s Facebook, Instagram or other social media platforms, their reviews, ratings and comments can be used to launch well-informed promotional campaigns and advertisements.
Indian banking perspective –SBI
State Bank of India (SBI) is a prominent player in data science banking in the Asian region. SBI with its 24,000-strong branch network, and overseas presence in 36 countries with 191 branches was the 216 biggest corporation in the world in the Fortune 500 list of biggest corporations, 2018.
SBI focused on data science in its banking well back in 2009. It has the world’s largest data centre with 170 TB of data, which is obvious considering its 300 m customer base.
SBI use its data analytics to categorise customers in to a scale of platinum, gold, etc. They have integrated a transfer pricing mechanism to this segmentation. Then they have used a predictive analysis model to forecast the potential product to be canvassed.
For instance, if a customer has a home and a regular performing credit card, and above average account balance, the customer may be spotted as a potential for a vehicle loan. NPA management is another area of practice. SBI identifies which loans are at risk of NPA, which can be recovered, etc. geographically as well as demographically through data analytics.
The data of credit bureaus (CIBIL, Equifax, Experian) such as CRIB data in Sri Lankan context, are also incorporated into the analytical models of SBI. SBI monitors customer money transfers to other banks using the narration included in the system. It helps data mining to generate leads on potential business opportunities. For example, if a customer is transferring money to another bank with the narration ‘Loan Repayment,’ SBI can utilise the information to canvass customer for a fresh loan at a better rate.
The future outlook
Each day at present 2.5 billion gigabytes of data are being generated. More than 3.7 billion people use the internet. How much searches does Google possess every second? It is 40,000 per second. In social media, Facebook alone has two billion active users. It is clear that the future is data driven.
Be it banking or any other sector, data science holds the key to the success. The intense competition in the banking industry will be compelled to embrace data science technology to overcome disruptions from competitors. Innovation and optimisation will be basics for survival.
However, the future is not without risk. Data science itself may subject to human bias as AI systems and machine learning are trained by humans. The datasets used to train the models may be subject to personal interests of the trainer, knowingly or unknowingly. The utmost risk possibility lies in data privacy.
A majority of major online firms such as Facebook are under increasing scrutiny over their use and sharing of data with third parties. Internet hackers on the other hand obtain a massive amount of data from spectrum of organisations. One place with a collection of massive data is an obvious target for hackers. Banking data is sensitive in nature and will be a more attractive destination for hackers. Any data breach of a bank will breach the trust of the bank in people and it may be wiped out of the business entirely. Although risks prevail, data science is the new reality of the modern world.
Can human creativity in its original form, be replicated in a machine? That we do not know. The answer lies in the future. But, as Darwin said, embracing change is essential for survival.
(The writer is a banker and an Associate member of the Institute of Bankers, currently attached to the Treasury division of the London branch of a Sri Lankan bank. He can be contacted via email at [email protected].)


